Intro
회사에서 Tableau를 사용하여 프로젝트를 진행할 일이 생기게 되면서 Tableau라는 툴에 대한 관심이 많아졌다. 데이터 시각화의 경우 D3.js와 Phthon의 라이브러리인 Seaborn 과 Matplotlib 정도만 사용해보았기에 Tableau에 적응하는 것은 매우 신선한(?) 작업이었다.
Tabpy
하지만, Tableau 프로그램에서 자체적으로 지원하는 분석 모델 및 예측 모델은 한정적이고, 속도에 대한 이슈도 존재했기 때문에 다른 방안을 알아보던 중 TabPy라는 분석 확장 프로그램을 찾게 되었다. Tableau 홈페이지에서는 TabPy에 대하여 데이터를 불러오기 전 전처리 작업이나 분석 및 예측 모델 등에 활용할 수 있다고 설명하고 있다. TabPy의 설치는 다음과 같은 환경에서 설치를 진행하였고, 사양은 다음과 같다.
설치 환경 및 사양
- Windows 10 Pro
- Python 3.8 (conda env)
- Tabpy == 2.4.0
- Tableau Desktop 2020.4
Installation
설치 방법은 다음의 절차로 진행하면 된다.
1. pip upgrade
python -m pip install --upgrade pip
2. tabpy install
pip install tabpy
3. tabpy 실행
tabpy
4. tabpy 실행체크
설치 완료 후 localhost의 9004번 포트에 접속해보면 TabPy 관련 화면이 출력되는 것을 확인할 수 있다.
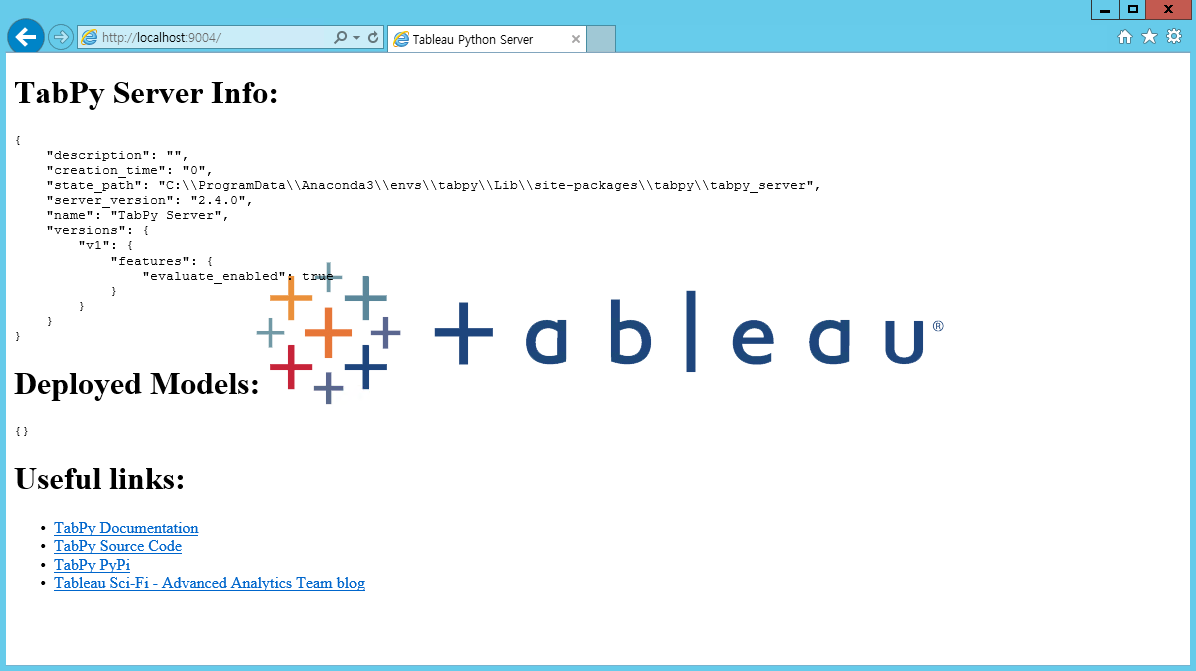
Test
TabPy를 활용하기에 앞서, Tableau Desktop과 TabPy Server를 연결시켜주어야 한다. TabPy 서버의 연결은 Tableau Desktop에서 ‘도움말 > 설정 및 성능 > Analytics 확장 프로그램 연결 관리’ 메뉴에서 연결해주면 된다. 연결이 성공하면 다음과 같은 화면이 출력된다.
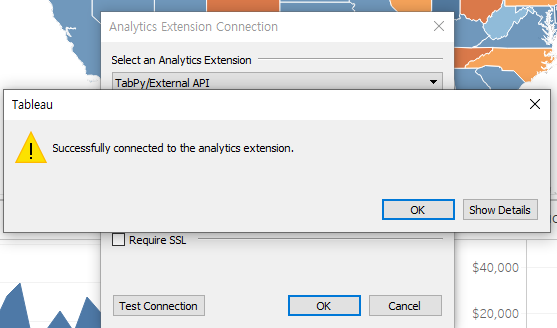
분석
기본으로 4가지의 분석 모델을 제공하고 있으며 관련 패키지는 다음의 명령어로 설치할 수 있다.
tabpy-deploy-models
4가지의 분석 모델은 다음과 같으며, 설치가 완료되면 9004번 포트의 화면에도 설치된 분석 모델이 출력되는 것을 확인할 수 있다.
- PCA (Principal Component Anaylsis)
- Sentiment Analysis
- T-Test
- ANOVA

예제 1
Sample - Superstore 활용예제 (np.corrcoef)
Tableau의 샘플 데이터셋인 Sueprstore 데이터에서 Numpy의 np.corrcoef 함수를 활용하는 예제이다. 테이블 계산을 Customer Name 기준으로 해서, Region별 Sales의 합과 Sub-Category별 Profit의 합 간 상관관계를 분석한다.
SCRIPT_REAL('
import numpy as np
return np.corrcoef(_arg1,_arg2)[0,1]
',
SUM([Sales]), SUM([Profit]))
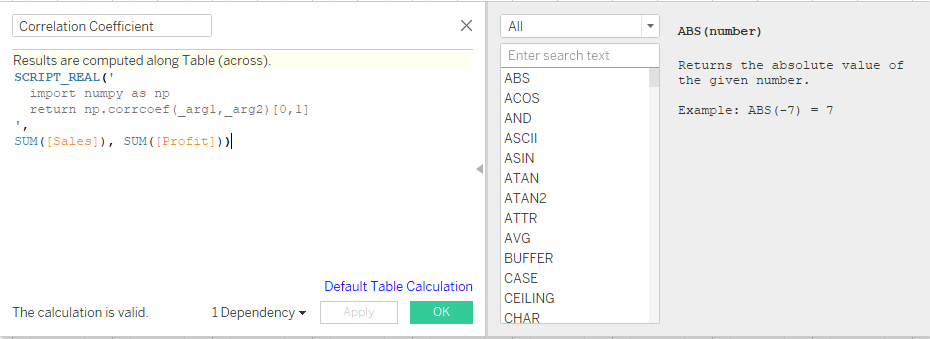
계산된 필드를 위와 같이 만들어 계산된 필드를 색상 범례로 추가하는 방식으로 활용할 수 있다.
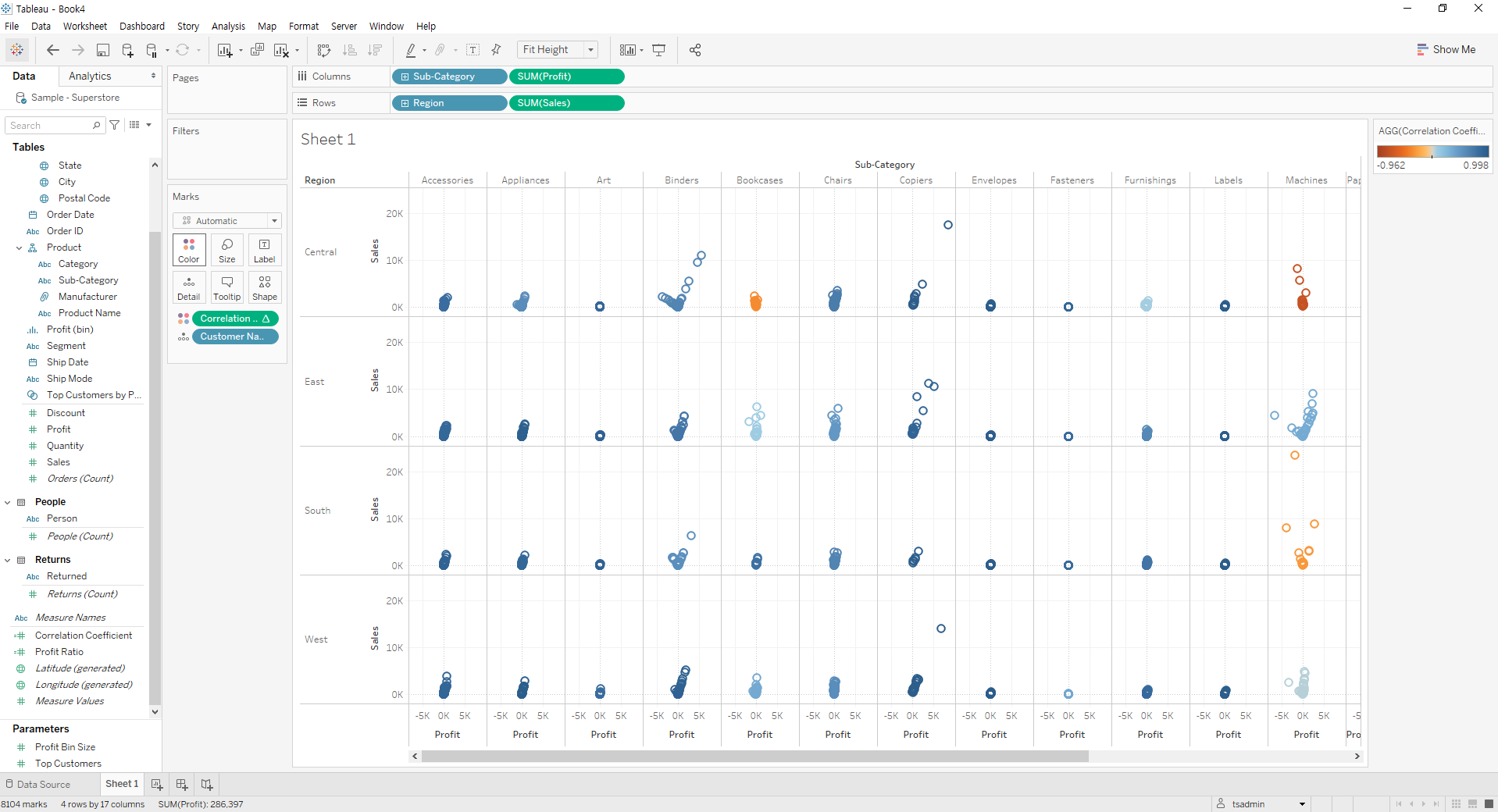
예제 2
Airbnb Data 활용예제
Airbnb 데이터셋을 사용하는 예제로, TabPy를 활용하여 클러스터링 기준을 생성하는 예제이다.
우선 Airbnb 데이터셋을 설치하여 Tableau에서 불러온다.
시트로 이동한 뒤, 클러스터링 범위를 조절할 때 사용하기 위하여 다음과 같이 Parameter를 생성한다.
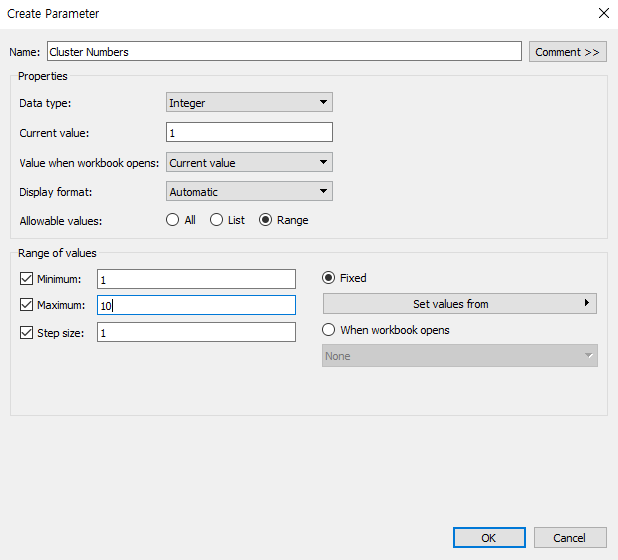
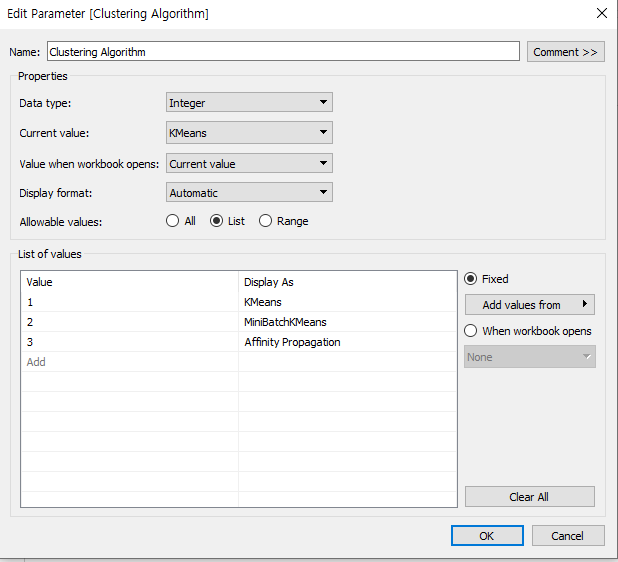
또한, 클러스터링 알고리즘을 변경할 때 사용하기 위하여 다음과 같이 Parameter를 추가 생성한다.
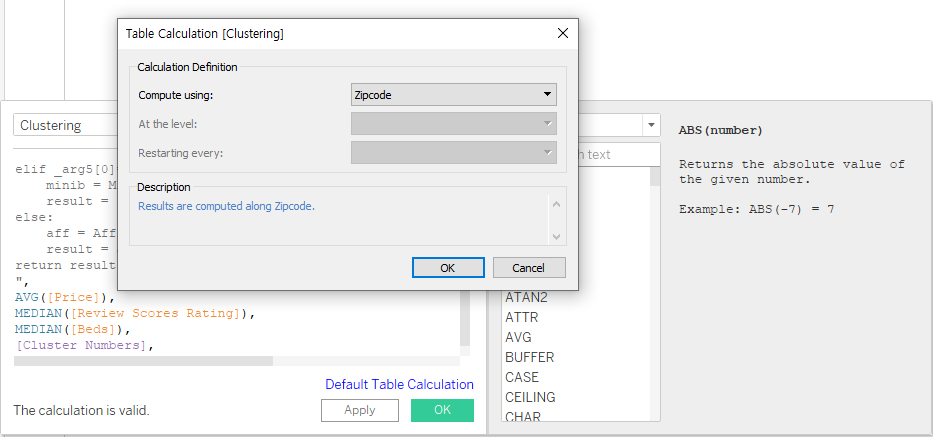
계산된 필드를 하단과 같이 생성한다.
STR(SCRIPT_REAL("
import numpy as np
import numpy.ma as ma
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans, MiniBatchKMeans, AffinityPropagation
print('Start')
# Scaling Features
sc= StandardScaler()
avg_price = sc.fit_transform(np.array(_arg1).reshape(-1,1))
med_review = sc.fit_transform(np.array(_arg2).reshape(-1,1))
med_beds = sc.fit_transform(np.array(_arg3).reshape(-1,1))
n_cl = _arg4[0]
# Combine Scaled feature
X_comb = np.column_stack([avg_price, med_review, med_beds])
# Handling null value with masked array
X = np.where(np.isnan(X_comb), ma.array(X_comb, mask=np.isnan(X_comb)).mean(axis=0), X_comb)
# Modeling
result = []
if _arg5[0]==1:
kmeans = KMeans(n_clusters = n_cl, random_state=99)
result = kmeans.fit_predict(X).tolist()
elif _arg5[0]==2:
minib = MiniBatchKMeans(n_clusters = n_cl, random_state=99)
result = minib.fit_predict(X).tolist()
else:
aff = AffinityPropagation().fit(X)
result = aff.predict(X).tolist()
return result
",
AVG([Price]),
MEDIAN([Review Scores Rating]),
MEDIAN([Beds]),
[Cluster Numbers],
[Clustering Algorithm]
))
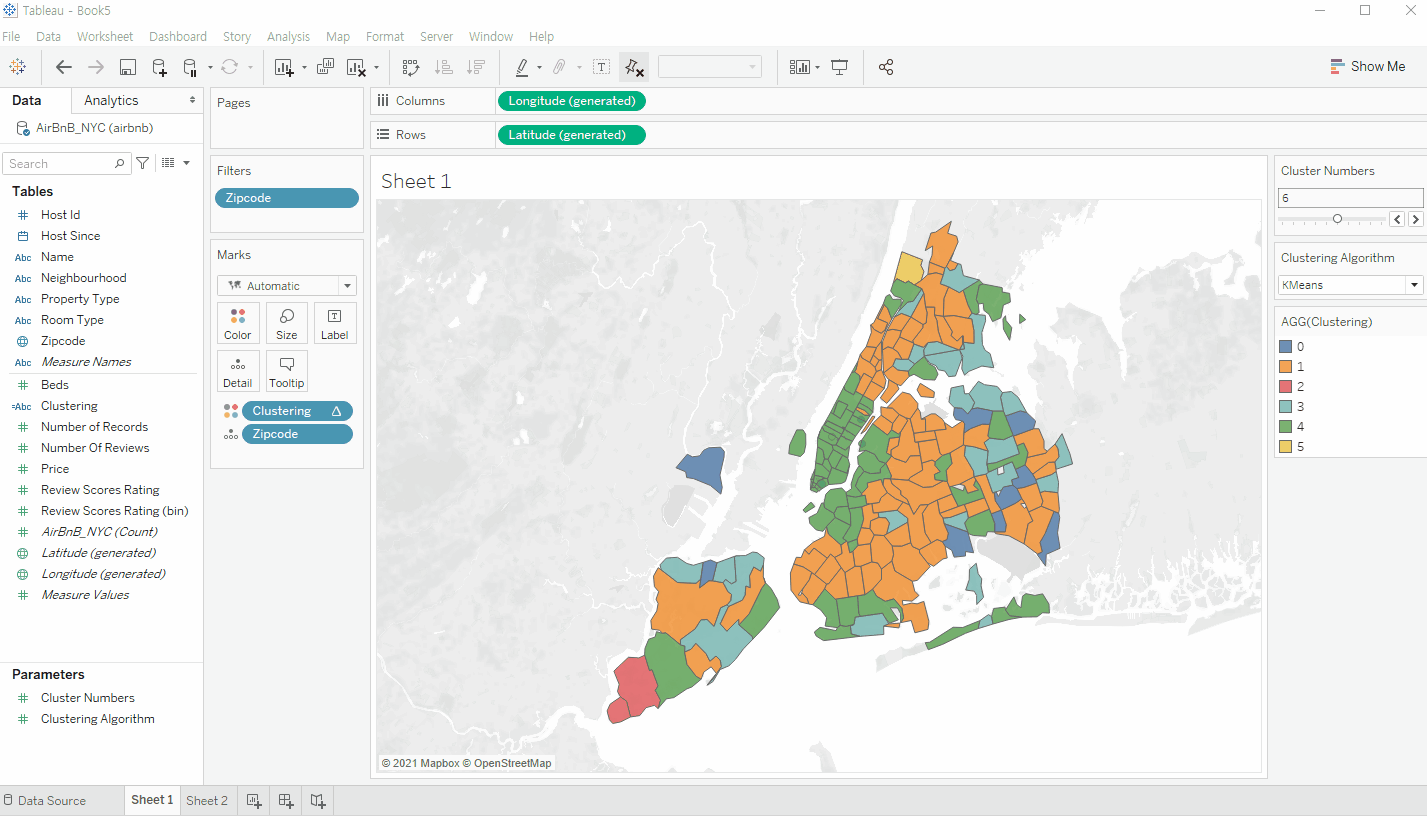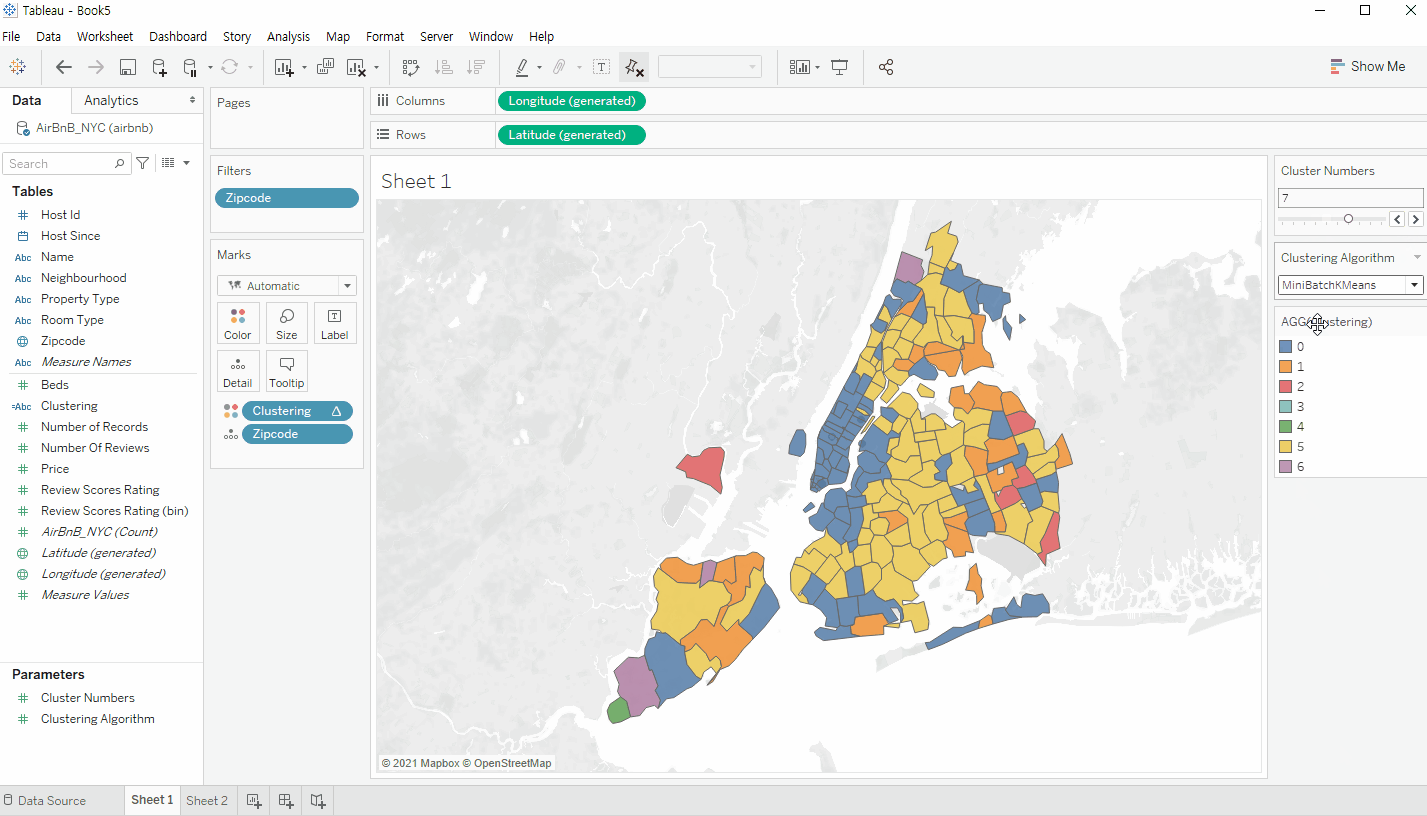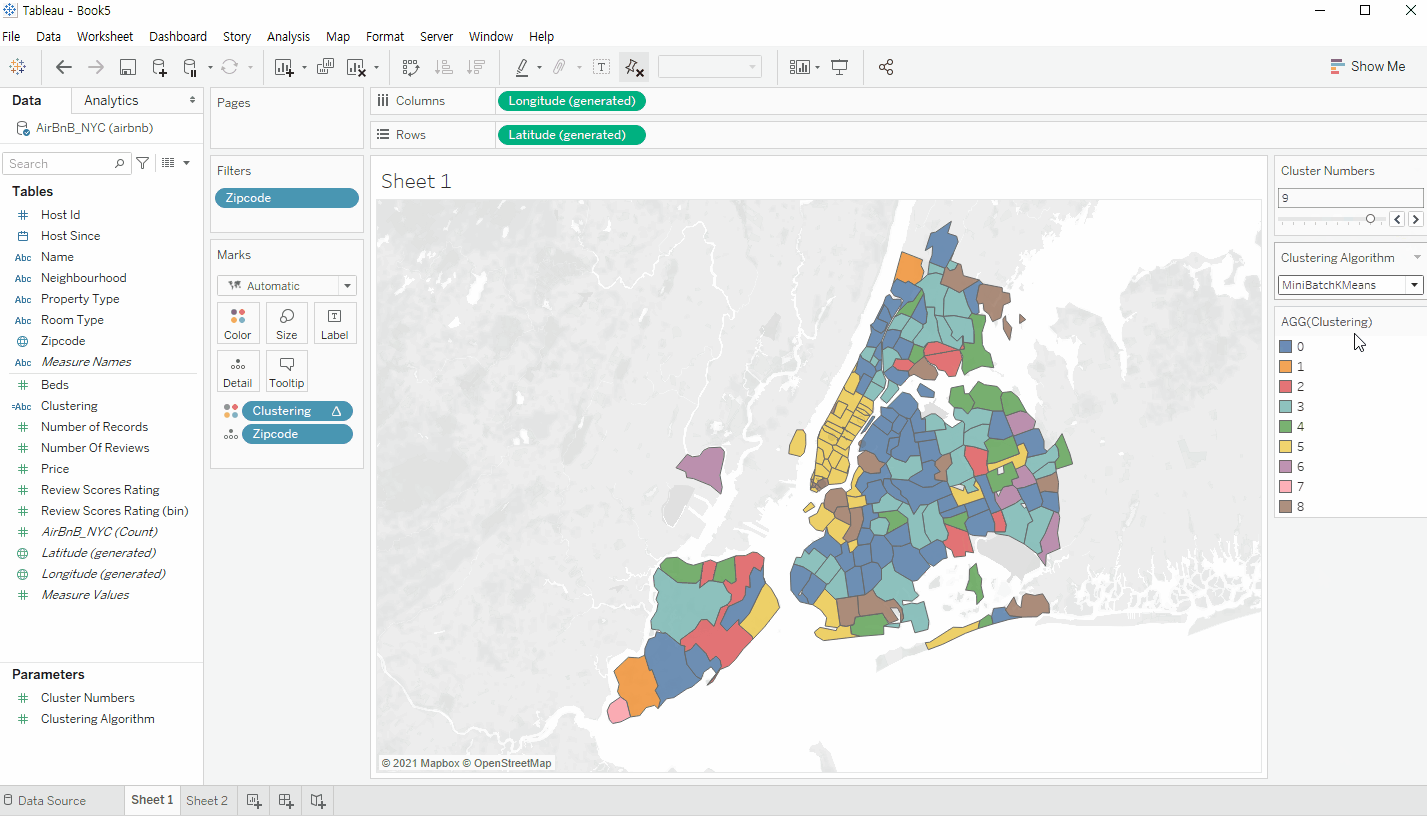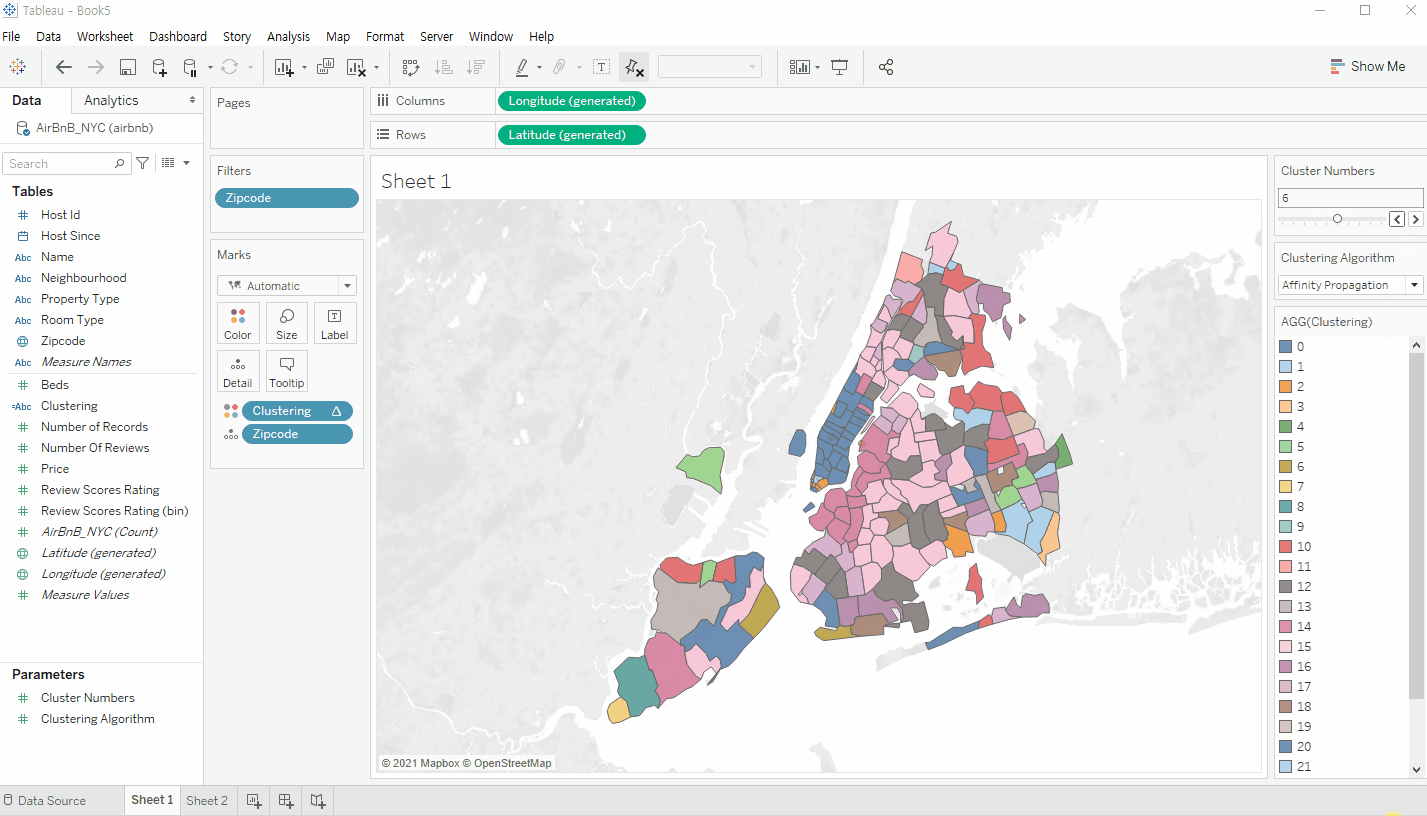
Zipcode 기준으로 시각화를 진행한다.
이후 위에서 생성한 Calculated Field를 색상 범례에 넣어서 클러스터링 기준으로 삼으면 다음과 같은 화면이 출력되는 것을 확인할 수 있다. 하단의 gif 이미지처럼 앞서 생성한 Parameter를 통하여 클러스터링 갯수와 알고리즘을 손쉽게 변경할 수 있다.
후기
TabPy를 활용해본 결과 Tableau의 필터와 계산된 필드만을 통해 계산을 진행할 때보다 훨씬 분석이 용이하다는 느낌을 받았다. 기존에 Python을 활용하여 데이터를 분석한 경험이 있는 사람이라면, TabPy를 활용하는 것이 오히려 더 편할 것이라 생각된다. Python과 더불어 통계 분석에 많이 활용되는 R의 경우에도 TabPy처럼 Rserve를 활용하여 서버의 형태로 연결하여 이용할 수 있는 것으로 보인다. 예제 위주로 Test만 진행해 본 것이기 때문에 많은 내용을 살펴보지는 못했으나 활용 방안은 상황에 따라 무궁무진할 것으로 예상된다.
활용 방안 아이디어
다음의 상황에서 TabPy를 활용할 수 있지 않을까 싶어 메모를 기록해둔다.
- 유사도 측정 시
- 여러 개의 feature를 하나로 합쳐 나타내야 할 때
- 예측 모델을 Python에서 가져와 계산에 활용
- 머신러닝으로 긍/부정 같이 이진 분류 후 시각화의 기준(Detail)으로 추가